2.2 Redes bayesianas
Ahora podemos definir red bayesiana:
Una red bayesiana es una gráfica GAD \({\mathcal G}\) junto con una distribución de probabilidad particular que se factoriza sobre \(G\).
Dado que \(p\) se factoriza sobre \(\mathcal G\), podemos usar la factorización para evitar dar explícitamente la conjunta sobre todas las posibles combinaciones de las variables. Es decir, podemos usar la parametrización dada por la factorización en condicionales.
Ejemplo. Sea \({\mathcal G}\) la siguiente gráfica
gr <- graph(c(1,2,3,2,2,4))
plot(gr,
vertex.label=c('llueve', 'mojado', 'regar', 'piso'),
layout = matrix(c(0, 1, 1, 0, 0, -1, 2, 0), byrow = TRUE, ncol = 2),
vertex.size = 20, vertex.color = 'salmon', vertex.label.cex = 1.2,
vertex.label.color = 'gray40', vertex.frame.color = NA, asp = 0.5,
edge.arrow.size = 1)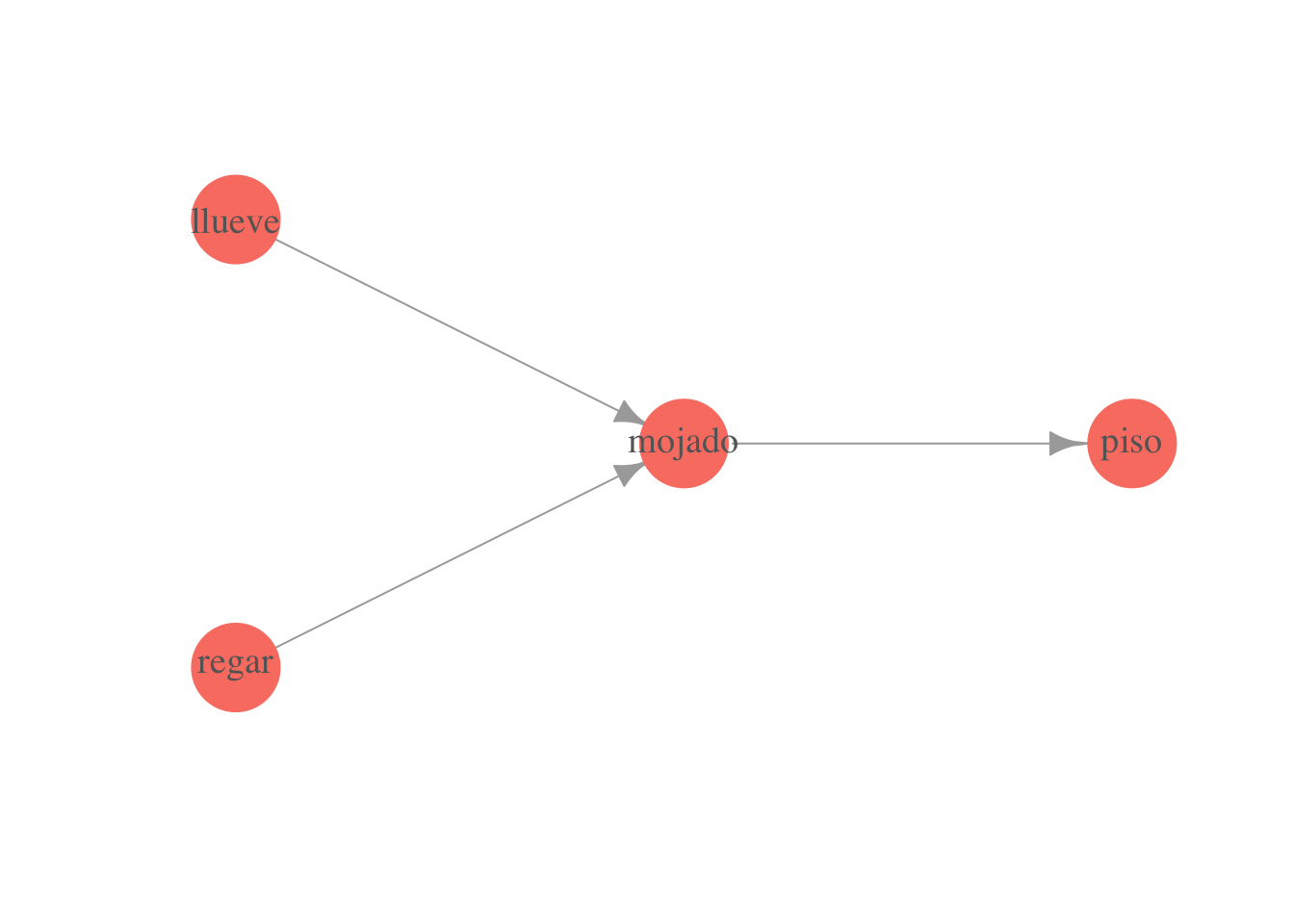
La conjunta \(p(m,l,r,z)\) (\(z\) es piso resbaloso) se factoriza como \[p(l)p(r)p(m|l,r)p(z|m)\]
En este ejemplo construiremos la red como si fuéramos los expertos. Esta es una manera de construir redes que ha resultado útil y exitosa en varias áreas (por ejemplo diagnóstico).
De forma que podemos construir una red bayesiana simplemente dando los valores de cada factor. En nuestro ejemplo, empezamos por las marginales de \(l\) y \(r\):
llueve <- c('No', 'Sí')
p_llueve <- data.frame(llueve = factor(llueve, levels= c("No", "Sí")),
prob_l = c(0.9, 0.1))
p_llueve
#> llueve prob_l
#> 1 No 0.9
#> 2 Sí 0.1
regar <- c('Apagado', 'Prendido')
p_regar <- data.frame(regar = factor(regar, levels = c('Apagado', 'Prendido')),
prob_r = c(0.7, 0.3))
p_regar
#> regar prob_r
#> 1 Apagado 0.7
#> 2 Prendido 0.3Ahora establecemos la condicional de mojado dado lluvia y regar:
mojado <- c('Mojado','Seco')
# los niveles son todas las combinaciones de los valores de las variables
niveles <- expand.grid(llueve = llueve, regar = regar, mojado = mojado)
# mojado|lluve,regar
p_mojado_lr <- data.frame(niveles, prob_m = NA)
p_mojado_lr$prob_m[1:4] <- c(0.02, 0.6, 0.7, 0.9)
p_mojado_lr$prob_m[5:8]<- 1 - p_mojado_lr$prob_m[1:4]
p_mojado_lr
#> llueve regar mojado prob_m
#> 1 No Apagado Mojado 0.02
#> 2 Sí Apagado Mojado 0.60
#> 3 No Prendido Mojado 0.70
#> 4 Sí Prendido Mojado 0.90
#> 5 No Apagado Seco 0.98
#> 6 Sí Apagado Seco 0.40
#> 7 No Prendido Seco 0.30
#> 8 Sí Prendido Seco 0.10Y finalmente la condicional de piso resbaloso dado piso mojado:
p_piso_mojado <- data.frame(expand.grid(
piso = c('Muy.resbaladizo', 'Resbaladizo', 'Normal'),
mojado=c('Mojado','Seco')))
p_piso_mojado
#> piso mojado
#> 1 Muy.resbaladizo Mojado
#> 2 Resbaladizo Mojado
#> 3 Normal Mojado
#> 4 Muy.resbaladizo Seco
#> 5 Resbaladizo Seco
#> 6 Normal Seco
p_piso_mojado$prob_p <- c(0.3, 0.6, 0.1, 0.02, 0.3, 0.68)
p_piso_mojado
#> piso mojado prob_p
#> 1 Muy.resbaladizo Mojado 0.30
#> 2 Resbaladizo Mojado 0.60
#> 3 Normal Mojado 0.10
#> 4 Muy.resbaladizo Seco 0.02
#> 5 Resbaladizo Seco 0.30
#> 6 Normal Seco 0.68Con esta información podemos calcular la conjunta. En este caso, como el problema es relativamente chico, podemos hacerlo explícitamente para todos los niveles:
p_1 <- inner_join(p_piso_mojado, p_mojado_lr)
#> Joining, by = "mojado"
p_2 <- inner_join(p_1, p_llueve)
#> Joining, by = "llueve"
p_conj <- inner_join(p_2, p_regar)
#> Joining, by = "regar"
p_conj$prob <- p_conj$prob_p * p_conj$prob_m * p_conj$prob_l * p_conj$prob_r
p_conj
#> piso mojado prob_p llueve regar prob_m prob_l prob_r
#> 1 Muy.resbaladizo Mojado 0.30 No Apagado 0.02 0.9 0.7
#> 2 Muy.resbaladizo Mojado 0.30 Sí Apagado 0.60 0.1 0.7
#> 3 Muy.resbaladizo Mojado 0.30 No Prendido 0.70 0.9 0.3
#> 4 Muy.resbaladizo Mojado 0.30 Sí Prendido 0.90 0.1 0.3
#> 5 Resbaladizo Mojado 0.60 No Apagado 0.02 0.9 0.7
#> 6 Resbaladizo Mojado 0.60 Sí Apagado 0.60 0.1 0.7
#> 7 Resbaladizo Mojado 0.60 No Prendido 0.70 0.9 0.3
#> 8 Resbaladizo Mojado 0.60 Sí Prendido 0.90 0.1 0.3
#> 9 Normal Mojado 0.10 No Apagado 0.02 0.9 0.7
#> 10 Normal Mojado 0.10 Sí Apagado 0.60 0.1 0.7
#> 11 Normal Mojado 0.10 No Prendido 0.70 0.9 0.3
#> 12 Normal Mojado 0.10 Sí Prendido 0.90 0.1 0.3
#> 13 Muy.resbaladizo Seco 0.02 No Apagado 0.98 0.9 0.7
#> 14 Muy.resbaladizo Seco 0.02 Sí Apagado 0.40 0.1 0.7
#> 15 Muy.resbaladizo Seco 0.02 No Prendido 0.30 0.9 0.3
#> 16 Muy.resbaladizo Seco 0.02 Sí Prendido 0.10 0.1 0.3
#> 17 Resbaladizo Seco 0.30 No Apagado 0.98 0.9 0.7
#> 18 Resbaladizo Seco 0.30 Sí Apagado 0.40 0.1 0.7
#> 19 Resbaladizo Seco 0.30 No Prendido 0.30 0.9 0.3
#> 20 Resbaladizo Seco 0.30 Sí Prendido 0.10 0.1 0.3
#> 21 Normal Seco 0.68 No Apagado 0.98 0.9 0.7
#> 22 Normal Seco 0.68 Sí Apagado 0.40 0.1 0.7
#> 23 Normal Seco 0.68 No Prendido 0.30 0.9 0.3
#> 24 Normal Seco 0.68 Sí Prendido 0.10 0.1 0.3
#> prob
#> 1 0.003780
#> 2 0.012600
#> 3 0.056700
#> 4 0.008100
#> 5 0.007560
#> 6 0.025200
#> 7 0.113400
#> 8 0.016200
#> 9 0.001260
#> 10 0.004200
#> 11 0.018900
#> 12 0.002700
#> 13 0.012348
#> 14 0.000560
#> 15 0.001620
#> 16 0.000060
#> 17 0.185220
#> 18 0.008400
#> 19 0.024300
#> 20 0.000900
#> 21 0.419832
#> 22 0.019040
#> 23 0.055080
#> 24 0.002040
sum(p_conj$prob)
#> [1] 1Usamos el paquete bnlearn para construir el objeto que corresponde a esta red bayesiana:
# nodos
graf_jardin <- empty.graph(c('llueve', 'regar', 'mojado', 'piso'))
# arcos
arcs(graf_jardin) <- matrix(c('llueve', 'mojado', 'regar', 'mojado', 'mojado',
'piso'), ncol = 2, byrow = T)
node.ordering(graf_jardin)
#> [1] "llueve" "regar" "mojado" "piso"
plot(graf_jardin)
modelo_jardin <- bn.fit(graf_jardin,
data = data.frame(p_conj[, c('llueve', 'regar', 'mojado', 'piso')]))Y este es el objeto que representa nuestra red (aunque falta corregir las probabilidades):
str(modelo_jardin)
#> List of 4
#> $ llueve:List of 4
#> ..$ node : chr "llueve"
#> ..$ parents : chr(0)
#> ..$ children: chr "mojado"
#> ..$ prob : 'table' num [1:2(1d)] 0.5 0.5
#> .. ..- attr(*, "dimnames")=List of 1
#> .. .. ..$ : chr [1:2] "No" "Sí"
#> ..- attr(*, "class")= chr "bn.fit.dnode"
#> $ regar :List of 4
#> ..$ node : chr "regar"
#> ..$ parents : chr(0)
#> ..$ children: chr "mojado"
#> ..$ prob : 'table' num [1:2(1d)] 0.5 0.5
#> .. ..- attr(*, "dimnames")=List of 1
#> .. .. ..$ : chr [1:2] "Apagado" "Prendido"
#> ..- attr(*, "class")= chr "bn.fit.dnode"
#> $ mojado:List of 4
#> ..$ node : chr "mojado"
#> ..$ parents : chr [1:2] "llueve" "regar"
#> ..$ children: chr "piso"
#> ..$ prob : 'table' num [1:2, 1:2, 1:2] 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5
#> .. ..- attr(*, "dimnames")=List of 3
#> .. .. ..$ mojado: chr [1:2] "Mojado" "Seco"
#> .. .. ..$ llueve: chr [1:2] "No" "Sí"
#> .. .. ..$ regar : chr [1:2] "Apagado" "Prendido"
#> ..- attr(*, "class")= chr "bn.fit.dnode"
#> $ piso :List of 4
#> ..$ node : chr "piso"
#> ..$ parents : chr "mojado"
#> ..$ children: chr(0)
#> ..$ prob : 'table' num [1:3, 1:2] 0.333 0.333 0.333 0.333 0.333 ...
#> .. ..- attr(*, "dimnames")=List of 2
#> .. .. ..$ piso : chr [1:3] "Muy.resbaladizo" "Resbaladizo" "Normal"
#> .. .. ..$ mojado: chr [1:2] "Mojado" "Seco"
#> ..- attr(*, "class")= chr "bn.fit.dnode"
#> - attr(*, "class")= chr [1:2] "bn.fit" "bn.fit.dnet"Ahora pondremos las probabilidades condicionales correctas (también llamados modelos locales):
tab_1 <- table(p_conj$llueve)
tab_1[c(1, 2)] <- p_llueve[, 2]
tab_1
#>
#> No Sí
#> 0.9 0.1
modelo_jardin$llueve <- tab_1
tab_2 <- table(p_conj$regar)
tab_2[c(1,2)] <- p_regar[,2]
tab_2
#>
#> Apagado Prendido
#> 0.7 0.3
modelo_jardin$regar <- tab_2
tab_3 <- xtabs(prob_m ~ mojado + llueve + regar, data = p_mojado_lr)
tab_3
#> , , regar = Apagado
#>
#> llueve
#> mojado No Sí
#> Mojado 0.02 0.60
#> Seco 0.98 0.40
#>
#> , , regar = Prendido
#>
#> llueve
#> mojado No Sí
#> Mojado 0.70 0.90
#> Seco 0.30 0.10
modelo_jardin$mojado <- tab_3
tab_4 <- xtabs(prob_p ~ piso + mojado, data = p_piso_mojado)
tab_4
#> mojado
#> piso Mojado Seco
#> Muy.resbaladizo 0.30 0.02
#> Resbaladizo 0.60 0.30
#> Normal 0.10 0.68
modelo_jardin$piso <- tab_4
modelo_jardin
#>
#> Bayesian network parameters
#>
#> Parameters of node llueve (multinomial distribution)
#>
#> Conditional probability table:
#>
#> No Sí
#> 0.9 0.1
#>
#> Parameters of node regar (multinomial distribution)
#>
#> Conditional probability table:
#>
#> Apagado Prendido
#> 0.7 0.3
#>
#> Parameters of node mojado (multinomial distribution)
#>
#> Conditional probability table:
#>
#> , , regar = Apagado
#>
#> llueve
#> mojado No Sí
#> Mojado 0.02 0.60
#> Seco 0.98 0.40
#>
#> , , regar = Prendido
#>
#> llueve
#> mojado No Sí
#> Mojado 0.70 0.90
#> Seco 0.30 0.10
#>
#>
#> Parameters of node piso (multinomial distribution)
#>
#> Conditional probability table:
#>
#> mojado
#> piso Mojado Seco
#> Muy.resbaladizo 0.30 0.02
#> Resbaladizo 0.60 0.30
#> Normal 0.10 0.68Finalmente, para hacer inferencia en la red (es decir, calcular probabilidades dado cierto conocimiento), necesitamos usar un algoritmo eficiente (por ejemplo en SAMIAM o GeNIe). Aquí usamos el paquete gRain. Los query que hacemos son la inferencia, pero también se llaman así en la literatura de modelos gráficos. En este caso, podemos examinar las marginales condicionales a toda la evidencia (información) que tenemos.
Por ejemplo, ¿cómo se ven las marginales cuando sabemos que el piso está muy resbaladizo?
library(gRain)
#> Loading required package: gRbase
#>
#> Attaching package: 'gRbase'
#> The following objects are masked from 'package:bnlearn':
#>
#> ancestors, children, parents
#> The following object is masked from 'package:igraph':
#>
#> topo_sort
comp_jardin <- compile(as.grain(modelo_jardin))
querygrain(comp_jardin)
#> $llueve
#> llueve
#> No Sí
#> 0.9 0.1
#>
#> $regar
#> regar
#> Apagado Prendido
#> 0.7 0.3
#>
#> $mojado
#> mojado
#> Mojado Seco
#> 0.2706 0.7294
#>
#> $piso
#> piso
#> Muy.resbaladizo Resbaladizo Normal
#> 0.095768 0.381180 0.523052
query_1 <- setEvidence(comp_jardin, nodes = c('piso'),
states = c('Muy.resbaladizo'))
querygrain(query_1)
#> $llueve
#> llueve
#> No Sí
#> 0.7773787 0.2226213
#>
#> $regar
#> regar
#> Apagado Prendido
#> 0.3058224 0.6941776
#>
#> $mojado
#> mojado
#> Mojado Seco
#> 0.8476735 0.1523265Podemos ver que llueve y mojado son independientes (sin condicionar).
query_2 <- setEvidence(comp_jardin, nodes = c('llueve'), states = c('Sí'))
querygrain(query_2)$regar
#> regar
#> Apagado Prendido
#> 0.7 0.3
query_3 <- setEvidence(comp_jardin, nodes = c('llueve'), states = c('No'))
querygrain(query_2)$regar
#> regar
#> Apagado Prendido
#> 0.7 0.3Y ahora vemos la dependencia entre llueve y regar si condicionamos a piso resbaladizo:
query_4 <- setEvidence(comp_jardin, nodes = c('piso', 'regar'),
states = c('Muy.resbaladizo', 'Apagado'))
querygrain(query_4)$llueve
#> llueve
#> No Sí
#> 0.5506692 0.4493308
query_5 <- setEvidence(comp_jardin, nodes = c('piso', 'regar'),
states = c('Muy.resbaladizo','Prendido'))
querygrain(query_5)$llueve
#> llueve
#> No Sí
#> 0.8772563 0.1227437 Abrir esta red en samiam, y
repetir los queries.
Abrir esta red en samiam, y
repetir los queries.
2.2.1 Independencia condicional y redes bayesianas
Ahora abordamos el segundo enfoque de las redes bayesianas. En este, leemos directamente independencias condicionales a partir de la estructura de la gráfica (es esencialmente equivalente al criterio de factorización).
Independencias condicionales locales
Una distribución de probabilidad \(p\in M({\mathcal G})\) (es decir, se factoriza en \(\mathcal G\)) si y sólo si para toda variable \(W\), \(W\) es condicionalmente independiente de cualquier variable que no sea su padre o descendiente dados los padres \(Pa(W)\). Es decir \[W \bot Z|Pa(W)\] para cualquier \(Z\) que no sea descendiente o padre de \(W\). Otra manera de decir esto es que dados los padres, un nodo sólo puede transmitir información probabilística a sus descendientes y a ningún otro nodo.
Por ejemplo, en la siguiente gráfica, el nodo rojo, dado los nodos azules, es condicionalmente independiente de los nodos grises:
gr <- graph(c(1, 4, 2, 5, 3, 5, 4, 6, 5, 6, 7, 8, 6, 8, 8, 9, 8, 10))
plot(gr,
vertex.size = 20,
vertex.color = c(rep('gray80', 3), rep('blue', 2), 'red', 'gray80', 'salmon',
'salmon', 'salmon'),
vertex.label.cex = 1.2, vertex.label.color = 'gray50', vertex.frame.color = NA,
asp = 0.7, edge.arrow.size = 1)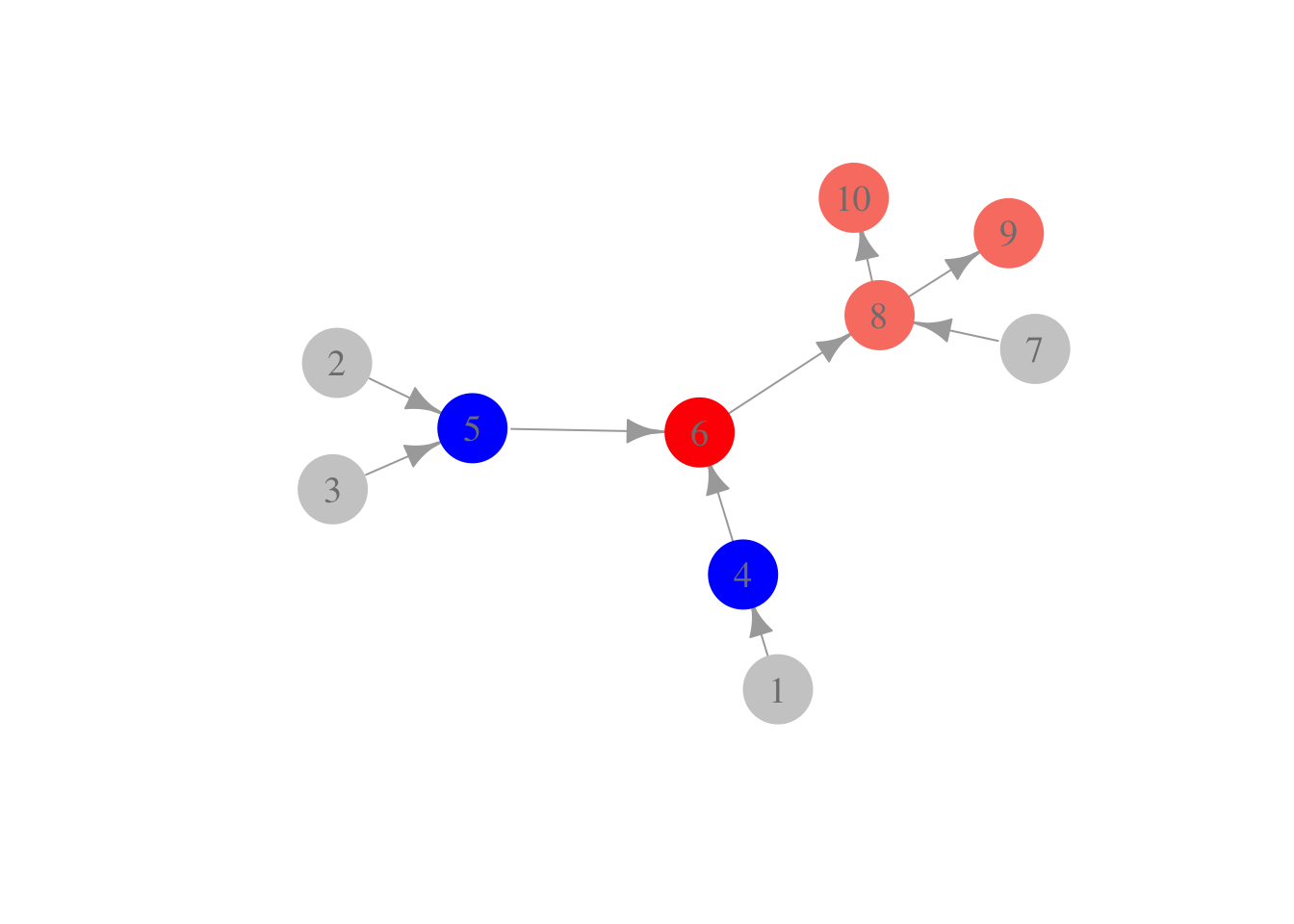
2.2.1.1 Discusión de demostración.
Supongamos que las independencias locales se satisfacen según el enunciado anterior. Si tomamos las variables según el orden topológico de \(\mathcal G\), dado por \(X_1,\ldots, X_k\), entonces por la regla del producto:
\[p(x)=\prod_{i=1}^k p(x_i|x_1,\ldots, x_{i-1}).\]
Ahora, nótese que 1) para cada \(X_i\), ninguna de las variables \(X_1,\ldots, X_{i-1}\) es descendiente de \(X_i\) y 2) que \(Pa(X_i)\) está contenido en \(X_1,\ldots, X_{i-1}\). Por lo tanto, por el supuesto de las independencias locales, vemos que \[p(x_i|x_1,\ldots, x_{i-1})=p(x_i|Pa(x_i)),\] y así hemos demostrado que \(p\) se factoriza en \(\mathcal G\).
El otro sentido de la demostración es más difícil, veamos un ejemplo. En la siguiente gráfica, describimos una factorización para la conjunta de varias variables: inteligencia de un alumno, dificultad del curso, calificación obtenida en el curso, calificación obtenida en el examen GRE y si el alumno recibe o no una carta de recomendación de su profesor:
library(igraph)
gr <- graph( c(1,3,2,3,2,4,3,5) )
plot(gr,
vertex.label = c('Dificultad','Inteligencia','Calificación','GRE',
'Recomendación'),
layout = matrix(c(-1,2,1,2,0,1,2,1,0,0), byrow = TRUE, ncol = 2),
vertex.size = 20, vertex.color = 'salmon', vertex.label.cex = 1.2,
vertex.label.color = 'gray40', vertex.frame.color = NA, asp = 0.5,
edge.arrow.size = 1)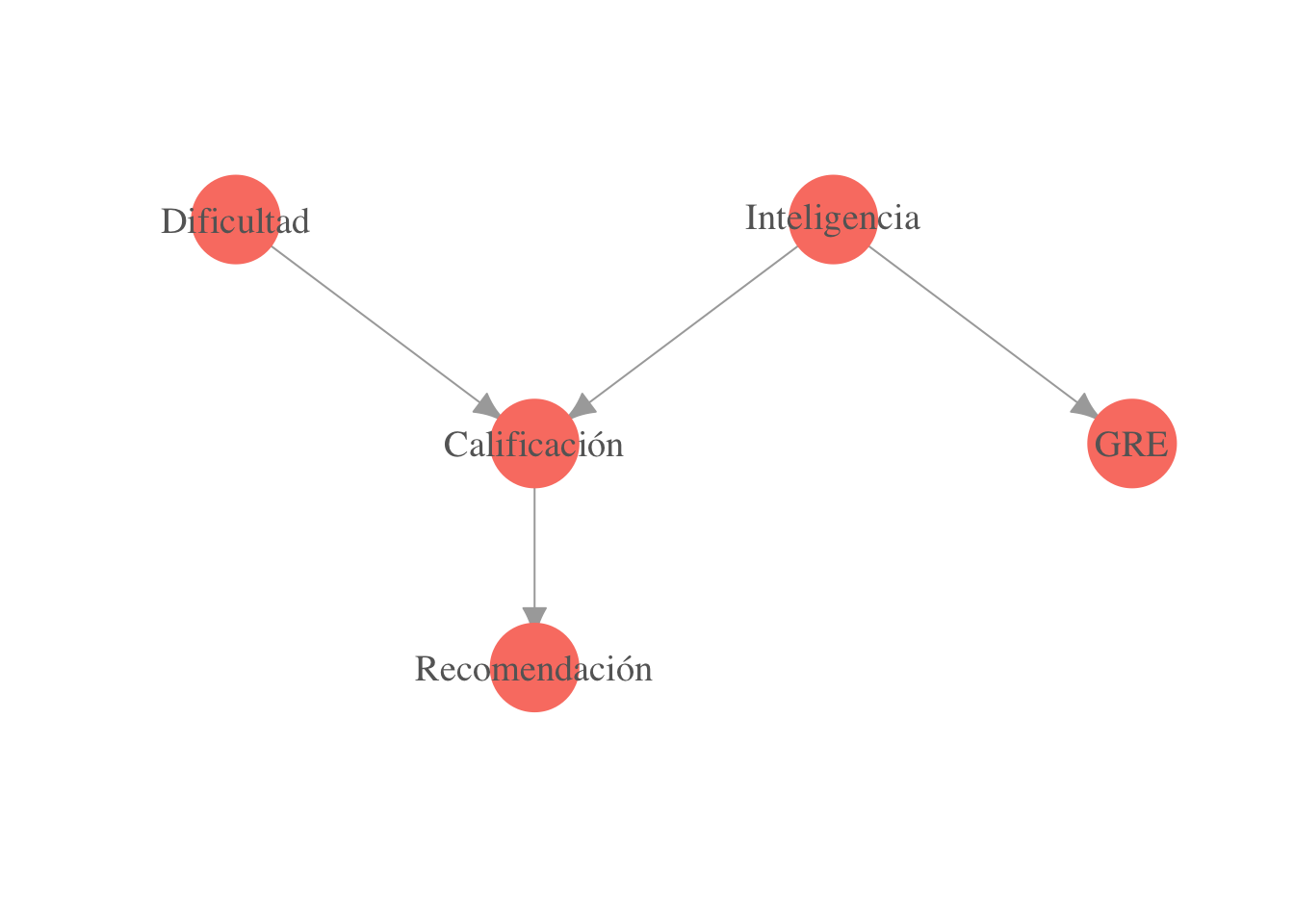
La conjunta se factoriza como \[p(i,d,c,g,r)=p(i)p(d)p(c|d,i)p(g|i)p(r|c).\]
Queremos demostrar que dada la inteligencia, la calificación del GRE es condicionalmente independiente del resto de las variables (pues el resto no son ni padres ni descendientes de GRE), es decir, busamos demostrar que
\[p(g|i,d,c,r)=p(g|i).\]
Comenzamos por la factorización de arriba: \[p(i,d,c,g,r)=p(i)p(d)p(c|d,i)p(g|i)p(r|c).\] Necesitamos calcular \[p(g|i,d,c,r)=\frac{p(g,i,d,c,r)}{p(i,d,c,r)}.\] Así que comenzamos con la factorización y sumamos sobre \(s\) para obtener \[p(i,d,c,r)=\sum_g p(i)p(d)p(c|d,i)p(g|i)p(r|c),\] \[p(i,d,c,r)=p(i)p(d)p(c|d,i)p(r|c),\] y dividiendo obtenemos que \[p(g|i,d,c,r)=p(g|i),\] que era lo que queríamos demostrar.
De acuerdo a la gráfica, la calificación en el GRE es independiente de la dificultad una vez que conocemos la inteligencia, es decir \(p(g | i, d) = p(g | i)\), veamos la factorización. Usando el teorema de Bayes podemos calcular la densidad condicional como,
\[p(g|i,d) = \frac{p(g,i,d)}{p(i,d)}\]
Ahora, comencemos calculando la densidad marginal \(p(g,i,d)\):
\[\begin{align}
\nonumber
p(g,i,d) &= \sum_c \sum_r p(i,d,c,r)
\nonumber
&= \sum_c \sum_r p(i)p(d)p(c|d,i)p(g|i)p(r|c)
\nonumber
&= \sum_c p(i)p(d)p(c|d,i)p(g|i)\sum_r p(r|c)
\nonumber
&= p(i)p(d)p(g|i) \sum_c p(c|d,i)
\nonumber
&= p(i)p(d)p(g|i)
\end{align}\]
Calculemos ahora el denominador en la regla de Bayes,
\[\begin{align}
\nonumber
p(i,d) &= \sum_g p(g,i,d)
\nonumber
&= \sum_g p(i)p(d)p(g|i)
\nonumber
&= p(i)p(d)\sum_g p(g|i)
\nonumber
&= p(i)p(d) \mbox{ (inteligencia y dificultad son indep.)}
\end{align}\]
Por lo tanto, la densidad condicional es
\[p(g|i,d) = \frac{p(g,i,d)}{p(i,d)} = \frac{p(i)p(d)p(g|i)}{p(i)p(d)} = p(g|i),\]
esto es, la calificación es independiente de la dificultad condicional a la
inteligencia del alumno.
Repetir para \(p(c|d,i)\).
Este último resultado explica cuáles son las independencias condicionales necesarias y suficientes para que una distribución se factorice según la gráfica \({\mathcal G}\). Ahora la pregunta que queremos resolver es: ¿hay otras independencias condicionales representadas en la gráfica? Buscamos independencias condicionales no locales. La respuesta es sí, pero necesitamos conceptos adicionales a los que hemos visto hasta ahora (d-separación).
Ejemplo. Antes de continuar, podemos ver un ejemplo de independencias no locales implicadas por la estructura gráfica. Si tenemos:
\[X \rightarrow Y \rightarrow Z \rightarrow W\]
es fácil ver que \(X\) es independiente de \(W\), dada \(Y\), aunque esta independencia no es de la forma del resultado anterior, pues no estamos condicionando a los padres de ningún vértice.
2.2.2 Flujo de información probabilística
En esta parte entenderemos primero como se comunica localmente la información probabilística a lo largo de los nodos cuando tenemos información acerca de alguno de ellos. Utilizaremos las factorizaciones implicadas por las gráficas asociadas.
¿En cuáles de los siguientes casos información sobre \(X\) puede potencialmente cambiar la distribución sobre \(Y\)?
- Razonamiento causal: \(X\rightarrow Z \rightarrow Y\)
Si no tenemos información acerca de \(Z\), \(X\) y \(Y\) pueden estar asociadas. En este caso tenemos \(p(x,y,z)=p(x)p(z|x)p(y|z)\), de forma que, haciendo un cálculo simple: \[p(x,y)= p(x) \sum_z p(y|z)p(z|x).\] Como siempre es cierto que \(p(x,y)=p(x)p(y|x)\), tenemos \[p(y|x)=\sum_z p(y|z)p(z|x),\] donde vemos que cuando cambia \(x\), puede cambiar también \(p(y|x)\).
En el ejemplo \(Edad \to Riesgo \to Accidente\), si alguien es más joven, entonces es más probable que sea arriesgado, y esto hace más probable que tenga un accidente.
Si sabemos el valor de \(Z\), sin embargo, \(X\) no nos da información de \(Y\). En este caso tenemos \(p(x,y)=p(x)p(z|x)p(y|z)\), como \(z\) está fija tenemos que \(p(x,y)=p(x)h(x)g(y)\), donde \(h\) y \(g\) son funciones fijas. Como la conjunta se factoriza, \(X\) y \(Y\) son independientes dada \(Z\).
En nuestro ejemplo, si conociemos la aversión al riesgo, la edad del asegurado no da información adicional acerca de la probabilidad de tener un accidente.
- Razonamiento evidencial: \(Y\rightarrow Z \rightarrow X.\)
Si no sabemos acerca de \(Z\), sí, por un argumento similar al del inciso anterior. Es un argumento de probabilidad inversa en \(Edad \to Riesgo \to Accidente\). Si alguien tuvo un accidente, entonces es más probable que sea arriesgado, y por tanto es más probable que sea joven.
Si sabemos el valor que toma \(Z\), entonces \(X\) no puede influenciar a \(Y\), por un argumento similar.
- Razonamiento de causa común: \(X\leftarrow Z \rightarrow Y\).
Sí, pues en este caso: \[p(x,y,z)=p(z)p(y|z)p(x|z),\] Sumando sobre \(z\) tenemos \[p(x,y)=\sum_z p(y|z)p(x,z),\] así que \(p(y|x)=\sum_z p(y|z)p(z|x).\)
En el ejemplo podríamos tener \(Tiempo manejando \leftarrow Edad \rightarrow Riesgo\). Una persona que lleva mucha tiempo manejando es más probablemente mayor, lo cual hace más probable que sea aversa al riesgo.
No. Si conocemos el valor de \(Z\), entonces \(X\) y \(Y\) son condicionalmente independientes, pues \(p(x,y,z)=p(z)p(y|z)p(x|z)\), donde vemos que una vez que está dada la \(z\) \(x\) y \(y\) no interactuán (están en factores distintos).
- Razonamiento intercausal: Colisionador o estructura-v: \(X\rightarrow Z \leftarrow Y\).
Si no tenemos información acerca de \(Z\), no. Esto es porque tenemos \[p(x,y,z)=p(x)p(y)p(z|x,y),\] de donde vemos que la conjunta de \(X\) y \(Y\) satisface \(p(x,y)=p(x)p(y)\) (sumando sobre \(z\)).
Podríamos tener que \(Calidad de conductor \rightarrow Accidente \leftarrow Condicion de calle\). Que alguien vaya por una calle en mal estado no cambia las probabilidades de ser un mal conductor (en nuestro modelo).
Si sabemos el valor de \(Z\), sí conocimiento de \(X\) puede cambiar probabilidades de \(Y\). Como tenemos \[p(x,y,z)=p(x)p(y)p(z|x,y),\] el término (z está fijo) \(p(z|x,y)=h(x,y)\) puede incluir interacciones entre \(x\) y \(y\).
En nuestro ejemplo, si sabemos que hubo un accidente, las condiciones de la calle si nos da información acerca de la calidad del conductor: por ejemplo, si la calle está en buen estado, se hace más probable que se trate de un conductor malo.
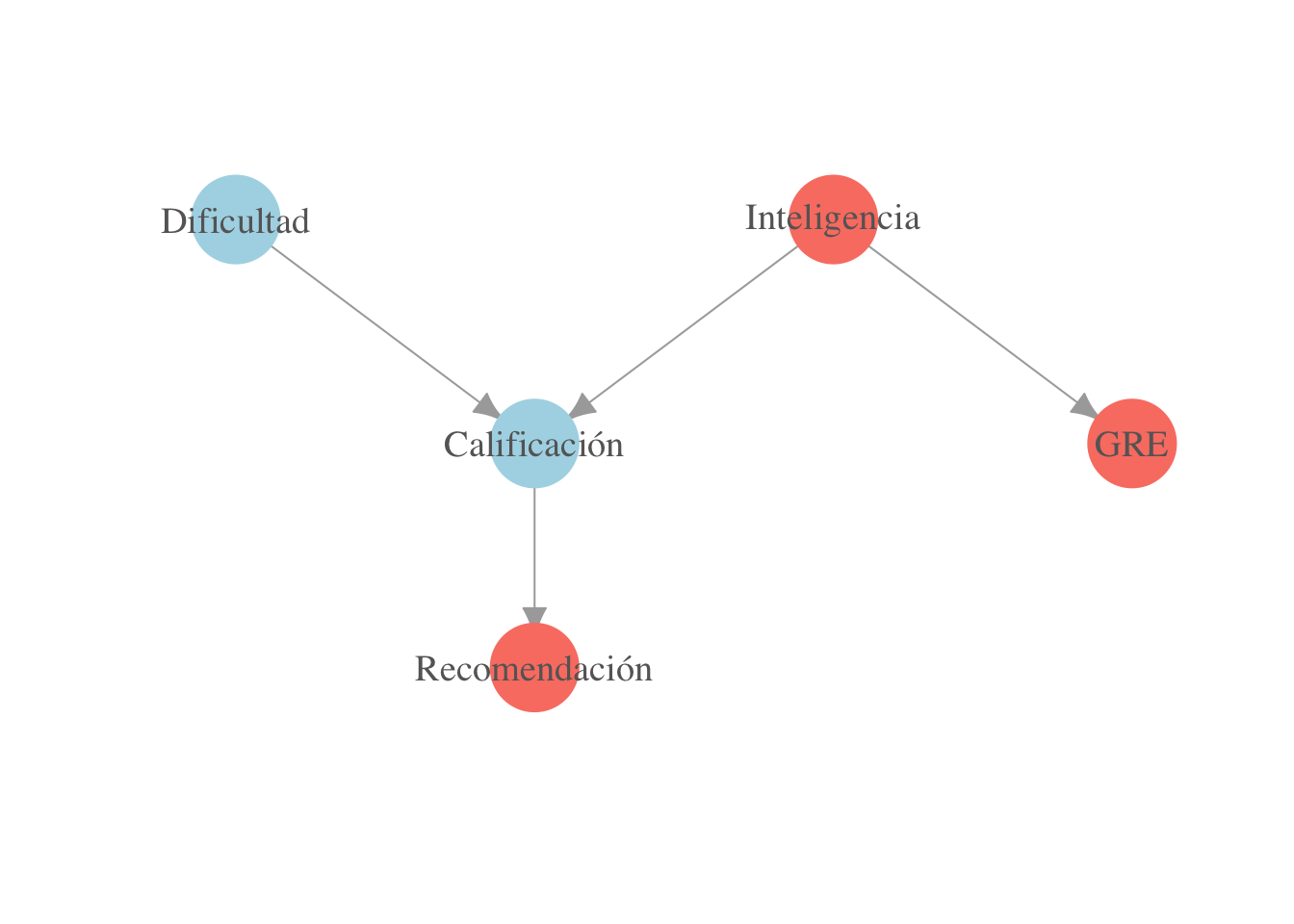
Si sabemos que la clase es difícil y que el estudiante obtuvo 6, ¿como cambia la probabilidad posterior de inteligencia alta? a) sube b) baja c) no cambia d) No se puede saber?
2.2.2.1 Caminos: pelota de Bayes
Un camino (no dirigido) esta activo si una pelota de Bayes que viaja a través del camino NO se topa con un símbolo de bloqueo (->|). En los esquemas los nodos sombreados indican que se tiene información de esas variables (ya no son aleatorios).
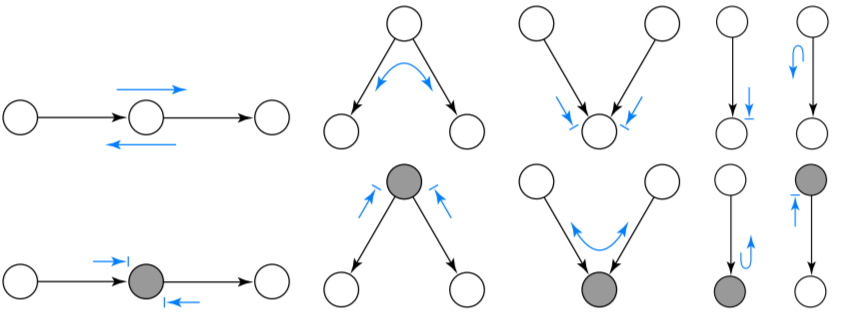
En la figura de la izquierda (abajo) notamos que (siguiendo las reglas de la pelota de Bayes) la pelota no puede llegar del nodo \(X\) al nodo \(Y\), esto es no existe un camino activo que conecte \(X\) y \(Y\). Por otra parte, la figura del lado derecho muestra que al condicionar en el conjunto \(\{X, W\}\) se activa un camino que permite que la pelota de Bayes viaje de \(X\) a \(Y\).
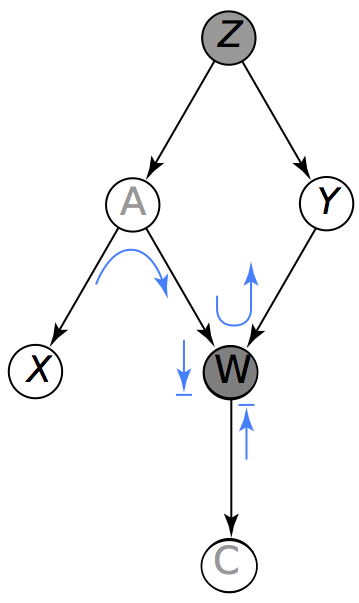
Ahora veamos alegbráicamente que si condicionamos únicamente a \(Z\), entonces \(X \perp Y | Z\), esto es lo que vemos en la figura de la izquierda. Para esto escribamos la densidad conjunta: \[p(z,a,y,x,b,c) = p(z)p(a|z)p(y|z)p(x|a)p(b|a,y)p(c|b)\] Y la utilizamos para obtener la densidad marginal \(p(x,y,z)\): \[\begin{align} \nonumber p(x,y,z) &= \sum_a \sum_b \sum_c p(z,a,y,x,b,c) \nonumber &= \sum_a \sum_b \sum_c p(z)p(a|z)p(y|z)p(x|a)p(b|a,y)p(c|b) \nonumber &= \sum_a \sum_b p(z)p(a|z)p(y|z)p(x|a)p(b|a,y)\sum_c p(c|b) \nonumber &= \sum_a p(z)p(a|z)p(y|z)p(x|a) \sum_b p(b|a,y) \nonumber &= p(z)p(y|z) \sum_a p(a|z) p(x|a) \nonumber &= g(y,z)h(x,z) \end{align}\] donde \(g(y,z) = p(z)p(y|z)\) y \(h(y,z) = \sum_a p(a|z) p(x|a)\). Por lo tanto \(X \perp Y | Z\).
Utilizando la gráfica del lado
derecho demuestra algebráicamente que dados \(Z,W\), \(X\) no es necesariamente
independiente de \(Y\).
2.2.3 Flujo de probabilidad y d-Separación
De la discusión anterior, definimos caminos activos en una gráfica los que, dada cierta evidencia \(Z\), pueden potencialmente transmitir información probabilística.
Sea \(U\) un camino no dirigido en una gráfica \({\mathcal G}\). Decimos que el camino es activo dada evidencia \(W\) si:
Todos los colisionadores en el camino \(U\) están o tienen un descendiente en \(W\).
- Ningún otro vértice de el camino está en \(W\).
Un caso adicional interesante es cuando los descendiente de un colisionador activan un camino.
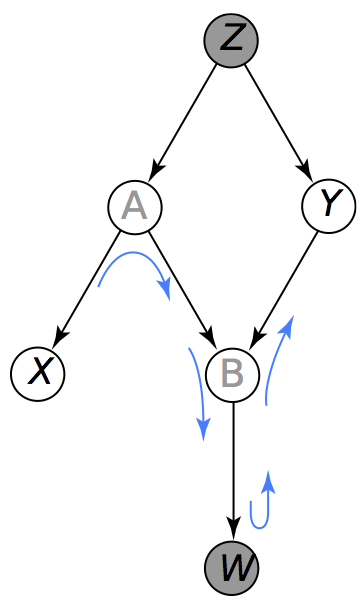
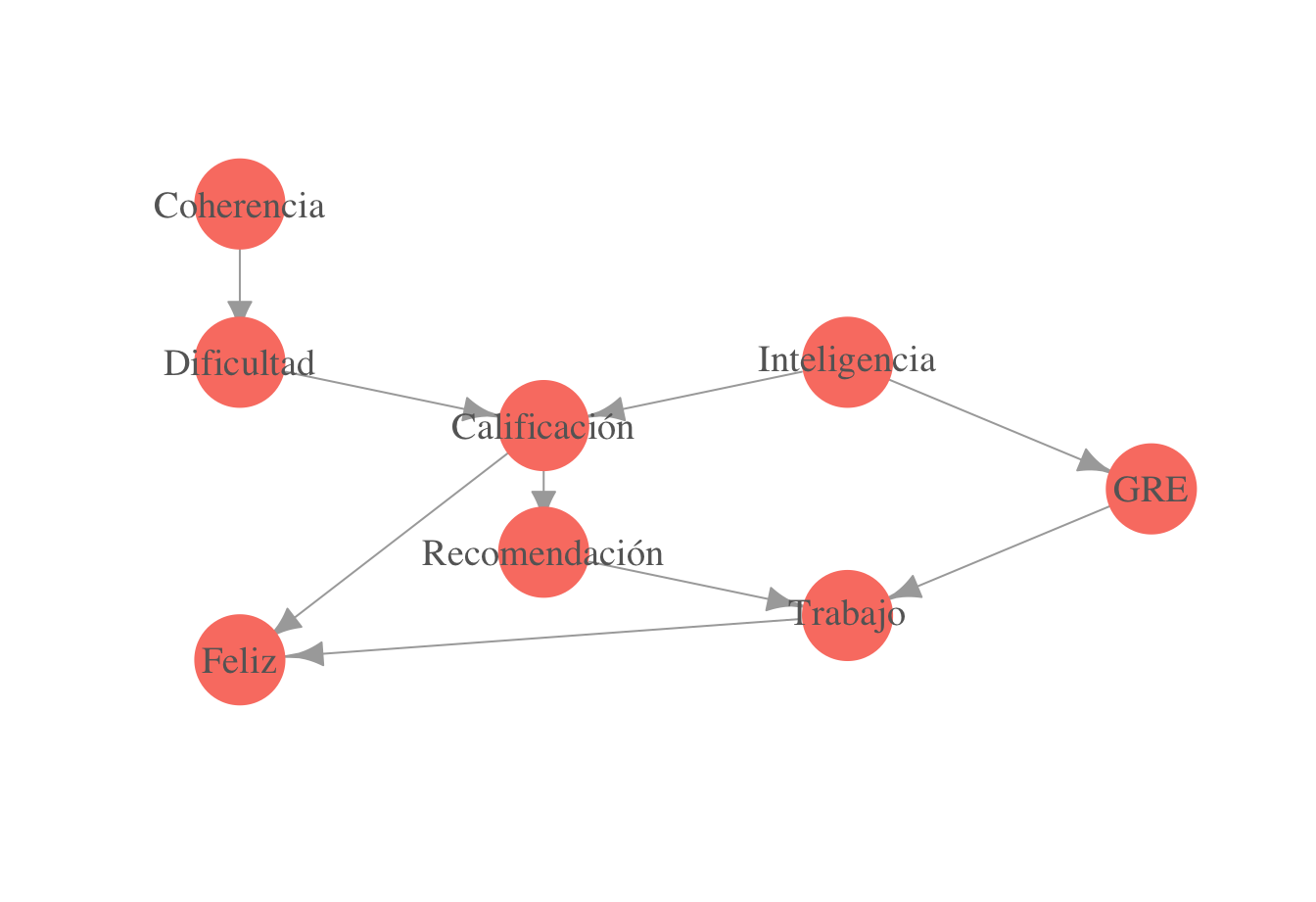
- ¿Cuáles de los siguientes son caminos activos si observamos Calificación?
- \(Coh \rightarrow Dif \rightarrow Calif \leftarrow Int \rightarrow GRE\)
- \(Int \rightarrow Cal \rightarrow Rec \leftarrow Tra \rightarrow Fel\)
- \(Int \rightarrow GRE \rightarrow Tra \rightarrow Fel\)
- \(Coh \rightarrow Dif \rightarrow Cal \leftarrow Int \rightarrow GRE \rightarrow Tra \leftarrow Rec\)
Volviendo al ejemplo anterior
Algebráicamente: La distribución conjunta se factoriza como: \[p(z,a,y,x,b,w)=p(z)p(a|z)p(y|z)p(x|a)p(b|a,y)p(w|b)\] Por lo que la marginal \(p(x,y,w,z)\) se obtiene de la siguiente manera: \[p(x,y,w,z) = \sum_a \sum_b p(z,a,y,x,b,w)\]
\[= \sum_a \sum_b p(z)p(a|z)p(y|z)p(x|a)p(b|a,y)p(w|b)\] \[= p(z)p(y|z) \sum_a p(a|z)p(x|a) \sum_b p(b|a,y)p(w|b)\]
Notamos que \(X\) y \(Y\) interactúan a través de \(A\) y \(B\), por lo que no es posible encontrar dos funciones \(g\), \(h\), tales que \(p(x,y,w,z) \propto g(x,w,z) h(y,w,z)\) y concluímos que \(X \not \perp Y | W\).
Sean \(X\) y \(Y\) vértices distintos y \(W\) un conjunto de vértices que no contiene a \(X\) o \(Y\). Decimos que \(X\) y \(Y\) están d-separados dada \(W\) si no existen caminos activos dada \(W\) entre \(X\) y \(Y\).
Es decir, la \(d\)-separación desaparece cuando hay información condicionada en colisionadores o descendientes de colisionadores.
Este concepto de \(d\)-separación es precisamente el que funciona para encontrar todas las independencias condicionales:
Supongamos que \(p\) se factoriza sobre \(\mathcal G\). Sean \(A\), \(B\) y \(C\) conjuntos disjuntos de vértices de \({\mathcal G}\). Si \(A\) y \(B\) están \(d\)-separados por \(C\) entonces \(A\bot B | C\) bajo \(p\) .
2.2.3.1 Discusión
El resultado anterior no caracteriza la independencia condicional de una distribución \(p\) por una razón simple, que podemos entender como sigue: si agregamos aristas a una gráfica \({\mathcal G}\) sobre la que se factoriza \(p\), entonces \(p\) se factoriza también sobre la nueva gráfica \({\mathcal G}'\). Esto reduce el número de independencias de \(p\) que representa \({\mathcal G}\).
Un ejemplo trivial son dos variables aleatorias independientes \(X\) y \(Y\) bajo \(p\). \(p\) claramente se factoriza en \(X\to Y\), pero de esta gráfica no se puede leer la independencia de \(X\) y \(Y\).
¿Qué es lo malo de esto? En primer lugar, si usamos \({\mathcal G}'\) en lugar de \({\mathcal G}\), no reducimos la complejidad del modelo al usar las independencias condicionales gráficas que desaparecen al agregar aristas. En segundo lugar, la independencia condicional no mostrada en la gráfica es más difícil de descubrir: tendríamos que ver directamente la conjunta particular de nuestro problema, en lugar de leerla directamente de la gráfica.
Finalmente, estos argumentos también sugieren que quisiéramos encontrar mapeos que no sólo sean mínimos (no se pueden eliminar aristas), sino también perfectos en el sentido de que representan exactamente las independencias condicionales. Veremos estos temas más adelante.
Algo que sí podemos establecer es cómo se comporta la familia de distribuciones que se factorizan sobre una gráfica \(\mathcal G\):
Sea \(\mathcal G\) una DAG. Si \(X\) y \(Y\) no están \(d\)-separadas en \(\mathcal G\), entonces existe alguna distribución \(q\) (que se factoriza sobre \({\mathcal G}\)) tal que \(X\) y \(Y\) no son independientes bajo \(q\).
Para que existan independencias que no están asociadas a \(d\)-separación los parámetros deben tomar valores paticulares. Este conjunto de valores es relativamente chico en el espacio de parámetros (son superficies), por lo tanto podemos hacer más fuerte este resultado:
Sea \(\mathcal G\) una DAG. Excepto en un conjunto de “medida cero” en el espacio de distribuciones \(M({\mathcal G})\) que se factorizan sobre \(\mathcal G\), tenemos que \(d\)-separación es equivalente a independencia condicional. Es decir, \(d\)-separación caracteriza precisamente las independencias condicionales de cada \(p\in M(\mathcal G)\), excepto para un conjunto relativamente chico de \(p \in M({\mathcal G})\) .
2.2.4 Equivalencia Markoviana
En esta parte trataremos el problema de la unicidad de la representación gráfica dada un conjunto de independencias condicionales. La respuesta corta es que las representaciones no son únicas, pues algunas flechas pueden reorientarse sin que haya cambios en términos de la conjunta representada.
Decimos que dos gráficas \({\mathcal G}_1\) y \({\mathcal G}_2\) son Markov equivalentes cuando el conjunto de independencias implicadas de ambas es el mismo. Otra manera de decir esto, es que ambas gráficas tienen exactamente la misma estructura de \(d-\)separación.
La equivalencia Markoviana limita nuestra capacidad de inferir la dirección de las flechas únicamente de las probabilidades, esto implica que dos gráficas Markov equivalentes no se pueden distinguir usando solamente una base de datos. Por ejemplo, en la siguiente gráfica, cambiar la dirección del arco que une \(X_1\) y \(X_2\) genera una gráfica Markov equivalente, esto es, la dirección del arco que une a \(X_1\) y \(X_2\) no se puede inferir de información probabilística.
library(igraph)
gr <- graph( c(1,2,1,3,2,4,3,4,4,5) )
plot(gr, vertex.label=c('X1','X2','X3','X4','X5'),
layout = matrix(c(-0.3,0,0,-0.3,0, 0.3,0.3,0,0.6,0), byrow = TRUE, ncol = 2),
vertex.size = 20, vertex.color = 'salmon', vertex.label.cex = 1.2,
vertex.label.color = 'gray40', vertex.frame.color = NA, asp = 0.5,
edge.arrow.size = 1)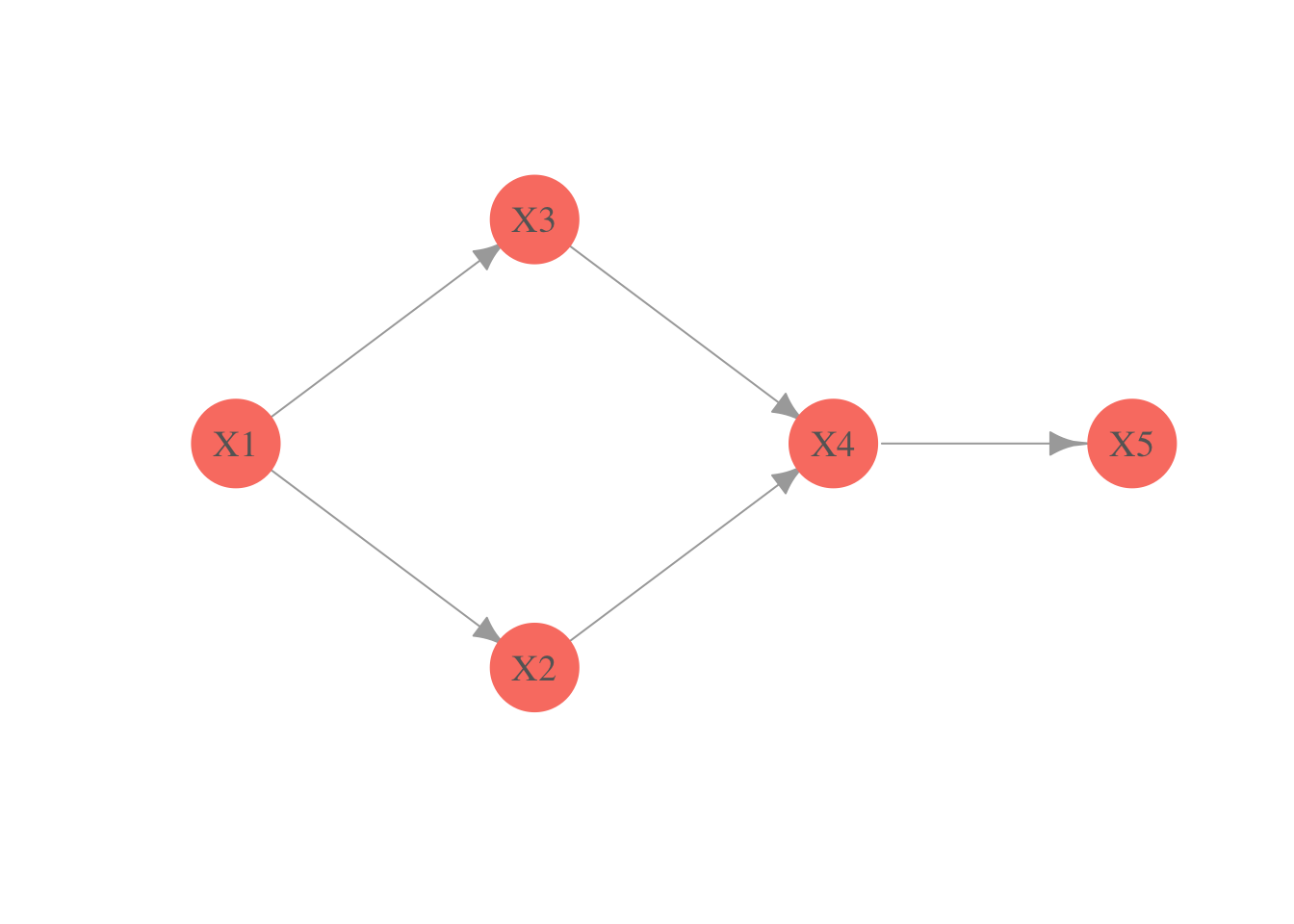
Decimos que un colisionador no está protegido cuando las variables que apuntan a la colisión no tienen vértice entre ellas. Definimos adicionalmente el esqueleto de una GAD como la versión no dirigida de \(\mathcal G\). El siguiente resultado establece que la distribución sólo puede determinar la dirección de las flechas en presencia de un colisionador no protegido:
Dos gráficas \({\mathcal G}_1\) y \({\mathcal G}_2\) son Markov equivalentes si y sólo si
Sus esqueletos son iguales y
- \({\mathcal G}_1\) y \({\mathcal G}_2\) tienen los mismos colisionadores no protegidos.
Las equivalencias que señala este teorema son importantes. Por ejemplo, las gráficas \(X\rightarrow Y \rightarrow Z\) y \(X\leftarrow Y \leftarrow Z\) son equivalentes, lo que implica que representan a las mismas distribuciones condicionales. Solamente usando datos (o el modelo), no podemos distinguir estas dos estructuras, sin embargo, puede ser que tengamos información adicional para preferir una sobre otra (por ejemplo, si es una serie de tiempo).
Una estructura que sí podemos identificar de manera dirigida es el colisionador. El resto de las direcciones pueden establecerse por facilidad de interpretación o razones causales.
Regresando a la gráfica anterior, notamos que al revertir el sentido del arco que une a \(X_1\) con \(X_2\) no se crea ni se destruye ningun colisionador y por tanto la gráfica resultante del cambio de sentido es efectivamente Markov equivalente. Consideremos ahora los arcos dirigidos que unen a \(X_2\) con \(X_4\) y a \(X_4\) con \(X_5\), notamos que no hay manera de revertir la dirección de estos arcos sin crear un nuevo colisionador, esto implica que algunas funciones de probabilidad \(p\) restringen la dirección de éstas flechas en la gráfica.
En el siguiente ejemplo, mostramos la clase de equivalencia de una red de ejemplo. Ahí vemos cuáles son las aristas que se pueden orientar de distinta manera, y cuáles pertenecen a colisionadores en los cuales las direcciones están identificadas:
library(bnlearn)
grafica.1 <- gs(insurance[c('Age', 'RiskAversion', 'Accident', 'DrivQuality',
'Antilock', 'VehicleYear')], alpha = 0.01)
graphviz.plot(grafica.1)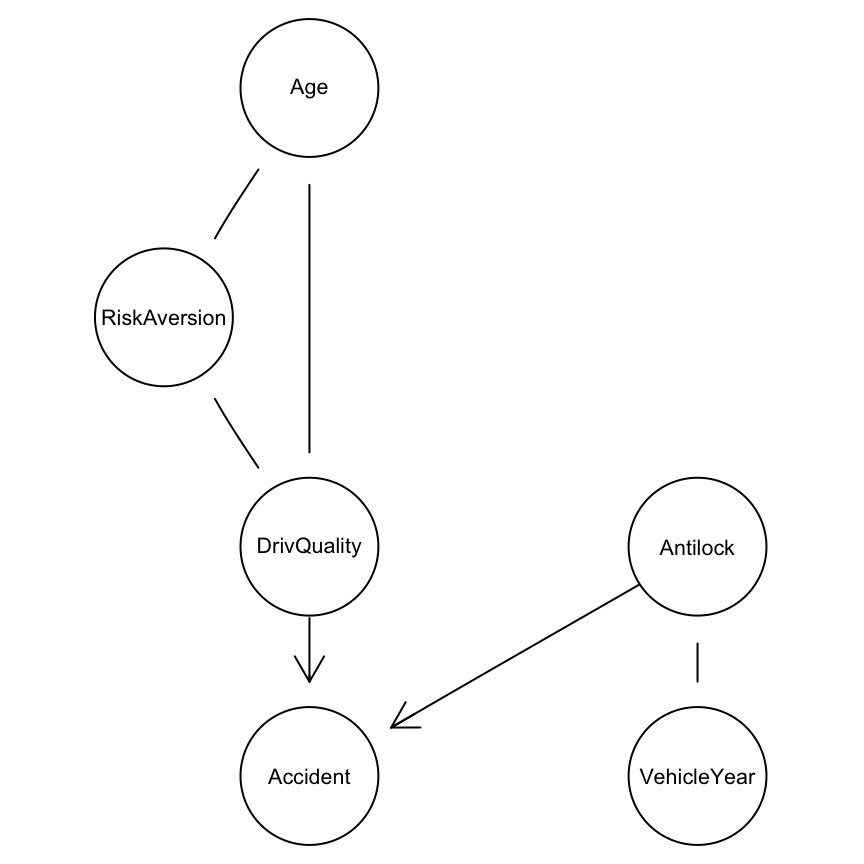
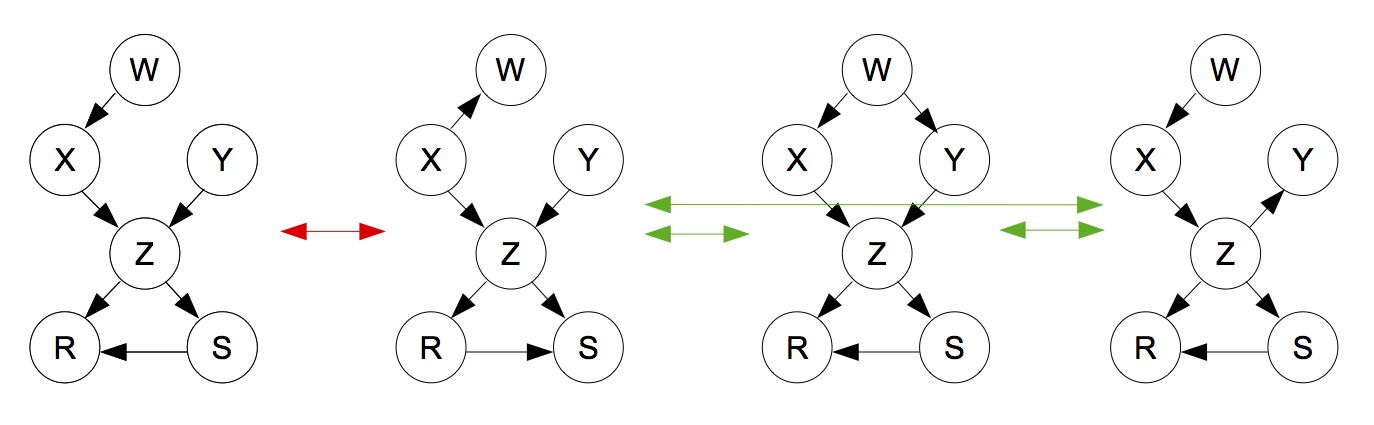
¿Cuáles de las gráficas anteriores son Markov equivalentes?
- 1 y 2
- 1 y 3
- 2 y 4
- 2 y 4
- Ninguna
Resumen
- Dada una gráfica \(G\) podemos encontrar las as independencias condicionales que
establece, \(I(G)\).
- Dada una distribución \(p\) podemos encontrar las independencias que implica, \(I(p)\) (en teoría).
- Las independencias condicionales definidas por la red bayesiana son un
subconjunto de las independencias en \(p\), esto es \(I(G) \subset I(p)\).
- Equivalencia Markoviana se expresa como: \(I(G) = I(G')\).